Retrieval Augmented Generation (RAG) with Spring, ReactJS, and PGVector
1. Introduction
In this tutorial, we’ll build a Retrieval Augmented Generation (RAG) Tool using Spring Boot, ReactJS, and PGVector. We’ll handle AI as a “magic box” that we can use to build cool stuff, without going too much into the details of the AI algorithms.
We’ll name it Smart Document Assistant, and it will be able to answer questions in a more specific way, based on the documents we provide.
We will build a simple interface to interact with the tool, feed it with documents and questions, and see the answers it provides.
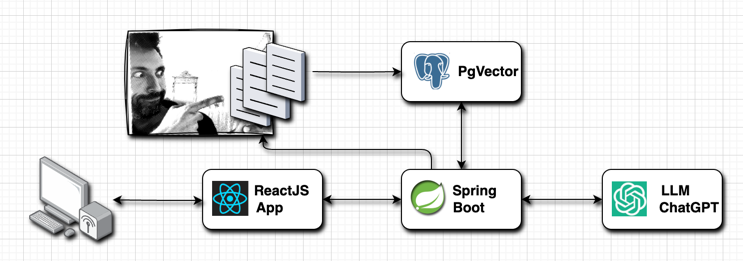
Basic Architecture diagram, made with Drawio
2. RAG and Vector Databases
Simply put, the Retrieval Augmented Generation is a way in which we can specialize Large Language Models to our needs, without spending money and resources on training a specific model for our needs.
Don’t be scared by the high-sounding naming: implementing a basic version of a RAG is trivial.
- We instruct the Model to answer following a template with placeholders for the documents
- We fill the template searching for relevant documents in the database
That’s it. It’s nothing more than prompt engineering, and absolutely not advanced Math and probabilities. This is the example template we will use in our Smart Document Assistant:
You are the Smart Document Assistant tool.
You are here to help with any questions about the documents in the DOCUMENTS section.
Use the conversation history from the HISTORY section to provide accurate answers.
HISTORY:
{history}
DOCUMENTS:
{documents}As you can see it has also a history section, that’ll contain the previous messages in the chat.
Filling the document section (that’s the only tricky bit here) is done by similarity search using our vector database. As you might imagine we could have millions of rows of documents, and it’s not the case to send the full documentation to the LLM to parse online for every request. So what we can do is filter the documents sending only the relevant bits.
PGVector for most aspects is pretty similar to a standard Postgres database. We can also build standard SQL tables in this database in the same exact way. (In fact, that’s what we are going to do to handle document uploads).
This is how it looks like browsing the table vector_store that contains our parsed documents from a Database Manager:

The vector_store table as seen from Dbeaver
That “embedding” column is the one that contains the vector representation of the document. We can use it to filter the documents that are more similar to the question we are asking.
The similarity search is implemented by converting the question to a vector and then querying the database for the most similar vectors. The similarity is calculated by evaluating the distance between two vectors - and for PgVector, the distance can be calculated in one of those three ways: Cosine, Euclidean, or Negative Inner Product.
3. Java IA Libraries
Java developers are trying to keep up with AI by providing libraries to interact with LLMs and Vector Databases in a smart way.
Right now currently the choice is between LangChain4j, SpringAI, and Semantic Kernel.
In this article, we will use Spring AI, because I am a SpringBoot aficionado, and because of autoconfiguration and Starters for AI Models. It’s amazing and makes us able to get rid of a lot of boilerplate. It provides API support across almost all chat AI providers, for several Vector Databases, simple Function calling, and even ETL framework for Data Engineering. But the best feature IMHO is the amazing documentation provided here. And no, I don’t get paid for this.
4. The React Application
The use cases are simple: on the left, we will have the chat to interact with the assistant, and on the right the list of documents that we have uploaded to the database, with a button to upload more.
<div className="app-container">
<Chat/>
<DocumentManager/>
</div>
A screenshot of the Assistant
4.1. The Chat Component
It’s Just a small component with some juicy tricks in order to make It scroll automatically when a message arrives. The important bits of this component are the rest calls done when pressing enter:
const message: ChatMessage = {
chatId,
message: input,
isResponse: false
};
setMessages((prevMessages) => [message, ...prevMessages ]);
const response = await assistantApi?.chat(message);
if(response)
setMessages((prevMessages) => [response.data, ...prevMessages])The chatId generation, that happens only once when the component is mounted. This parameter is used to keep track of the history of the conversation.
useEffect(() => {
setChatId(Date.now().toString());
}, []);4.2. The Document Manager Component
Nothing really special regarding this component; it’s Just a basic React component with a couple of standard functionalities to upload documents and display them in a list. It’s also possible to download and delete them. If curious just I encourage you to visit the repository linked at the end of the article.
5. The Spring Boot Application
Now the fun begins! First of all, we need a sprinkle of awesomeness in the form of Spring Libraries:
implementation("org.springframework.ai:spring-ai-openai-spring-boot-starter")
implementation("org.springframework.ai:spring-ai-pgvector-store-spring-boot-starter")
developmentOnly("org.springframework.boot:spring-boot-docker-compose")Other than the libraries to interact with pgvector and openai we also included the spring-boot-docker-compose, a library that will include automatically the behavior to start and stop the pg-vector database instance following the start and stop of our spring boot application. Alternatives to this can be running TestContainers as explained in this article. But in this case, it’s enough to add the following property in our application.yaml:
docker:
compose:
lifecycle-management: start-and-stopand this small compose.yaml file in the root folder:
services:
pgvector:
image: 'pgvector/pgvector:pg16'
environment:
- 'POSTGRES_DB=mydatabase'
- 'POSTGRES_PASSWORD=secret'
- 'POSTGRES_USER=myuser'
labels:
- "org.springframework.boot.service-connection=postgres"
ports:
- '5432:5432'The iteration between the SpringBoot App and the React App is made with REST methods. We have a couple of Controllers, that are linked to each React Component.
5.1 The Assistant Controller
The AssistantController it’s the only component that interacts with the LLM (ChatGPT in this case):
@PostMapping("chat")
public ResponseEntity<ChatMessage> chat(@RequestBody ChatMessage chatMessage) {
Flux<String> msg =
springAiAssistant.chat(chatMessage.getChatId(), chatMessage.getMessage());
...The SpringAIAssistant it’s the core of the LLM iteration, where we query the vector store database for similar documents, and we build the chat history to populate the Prompt we have seen in the “RAG and Vector Databases” chapter of this article. The similarityThreshold and the kNearestNeighbors are parameters set in the application.yaml that we can configure. We could also probably receive them directly from the user in a more advanced version of the application.
public Flux<String> chat(String chatId, String userMessageContent) {
// Retrieve related documents to query
SearchRequest request =
SearchRequest.query(userMessageContent)
.withSimilarityThreshold(similarityThreshold)
.withTopK(kNearestNeighbors);
List<Document> similarDocuments = this.vectorStore.similaritySearch(request);
if (CollectionUtils.isEmpty(similarDocuments)) return Flux.create(sink -> {
sink.next("I am sorry, I could not find any related documents to your query. Please try again.");
sink.complete();
});
Message systemMessage =
getSystemMessage(
similarDocuments,
this.chatHistory.getLastN(chatId, CHAT_HISTORY_WINDOW_SIZE));
logger.debug("System Message: {}", systemMessage.getContent());
UserMessage userMessage = new UserMessage(userMessageContent);
this.chatHistory.addMessage(chatId, userMessage);
// Ask the AI model
Prompt prompt = new Prompt(List.of(systemMessage, userMessage));
return this.chatClient.stream(prompt)
.map(
(ChatResponse chatResponse) -> {
if (!isValidResponse(chatResponse)) {
logger.warn("ChatResponse or the result output is null!");
return "";
}
AssistantMessage assistantMessage =
chatResponse.getResult().getOutput();
this.chatHistory.addMessage(chatId, assistantMessage);
return (assistantMessage.getContent() != null)
? assistantMessage.getContent()
: "";
});
}The chatHistory is a simple in-memory structure that keeps track of the last messages in the chat. We are sending to the prompt only the messages with the same chatId, and we add both the user and the assistant messages to the history to make the assistant more accurate in the answers.
The important bit here is that, apart from the chatHistory that is a custom class, all the other classes as the Prompt, the UserMessage, the AssistantMessage, etc., are provided by the Spring AI library thus helping us fasten the development process and helping us in defining a standard way to interact with the LLM, that we can learn and use in other projects.
5.3 The Document Controller
A couple of additional @Entity classes will be used to handle the vectors so that we can add and delete documents easily. The DocumentEntity will have a 1-N relationship with the vector_store table, that is managed through the spring-ai-pgvector-store-spring-boot-starter library.
@Entity
@Table(name = "document")
@Data
public class DocumentEntity {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Integer id;
@Column(name = "name")
private String name;
@Column(name = "type")
private String type;
@Column(name = "size")
private Long size;
@Column(name = "uploaded_at")
private Long uploadedAt;
@Column(name = "content")
private byte[] content;
@OneToMany(mappedBy = "documentId", fetch = FetchType.LAZY)
private List<DocumentVectorStoreEntity> documentVectorStoreEntities;
}
@Entity
@Table(name = "document_vector_store")
@Data
public class DocumentVectorStoreEntity {
@Id
@Column(name = "vector_store_id")
private String vectorStoreId;
@Id
@Column(name = "document_id")
private Integer documentId;
}The DocumentController contains the basic CRUD methods to manage documents in the Vector database:
@RestController
@CrossOrigin
@RequestMapping("api/v1/document")
public class DocumentController {
@Autowired private DocumentService documentService;
/** Receive a file and store it in the database. */
@PostMapping("/file")
public ResponseEntity<DocumentDTO> uploadFile(
@RequestParam("file") MultipartFile file, @RequestParam("name") String name)
throws IOException {
return ResponseEntity.ok(documentService.uploadFile(file, name));
}
/** Download the document by its id. */
@GetMapping("/download/{id}")
public ResponseEntity<InputStreamResource> download(@PathVariable Integer id) {
MediaType contentType = MediaType.TEXT_PLAIN;
return ResponseEntity.ok()
.contentType(contentType)
.body(new InputStreamResource(documentService.download(id)));
}
/** Delete the document and related vector store documents. */
@DeleteMapping("/{id}")
public ResponseEntity<Void> delete(@PathVariable Integer id) {
documentService.delete(id);
return ResponseEntity.ok().build();
}
// Other methods...
}When we upload the document, the DocumentService will parse the text and store it in the vector store. Then it will save the document in the document table and link it to the vector store documents.
The TokenTextSplitter is a utility class that will split the text into chunks of a certain size. This is useful to avoid sending the full text to the LLM and to make the similarity search more efficient. Of course, fine-tuning those parameters is a matter of experimentation, and it’s related to the specific document we are parsing. Garbage-in Garbage-out applies here as well.
int defaultChunkSize = 30;
int minChunkSizeChars = 20;
int minChunkLenghtToEmbed = 1;
int maxNumChunks = 10000;
boolean keepSeparator = true;
List<Document> vectorStoreDocuments =
new TokenTextSplitter(defaultChunkSize, minChunkSizeChars, minChunkLenghtToEmbed, maxNumChunks, keepSeparator)
.apply(new TextReader(file.getResource()).get());
vectorStore.accept(vectorStoreDocuments);
DocumentEntity documentEntity = new DocumentEntity();
documentEntity.setName(name);
documentEntity.setSize(file.getSize());
documentEntity.setType(file.getContentType());
documentEntity.setUploadedAt(System.currentTimeMillis());
documentEntity.setContent(file.getBytes());
documentEntity.setDocumentVectorStoreEntities(
vectorStoreDocuments.stream()
.map(
vectorStoreDocument -> {
DocumentVectorStoreEntity documentVectorStoreEntity =
new DocumentVectorStoreEntity();
documentVectorStoreEntity.setDocumentId(documentEntity.getId());
documentVectorStoreEntity.setVectorStoreId(
vectorStoreDocument.getId());
return documentVectorStoreEntity;
})
.collect(Collectors.toList()));
documentRepository.save(documentEntity);6. Conclusion and Final Test
To conclude this tutorial, let’s try to put the Smart Document Assistant to the test. Let’s feed all the content of this article (to this point) as a document and let’s see the output it prints out.
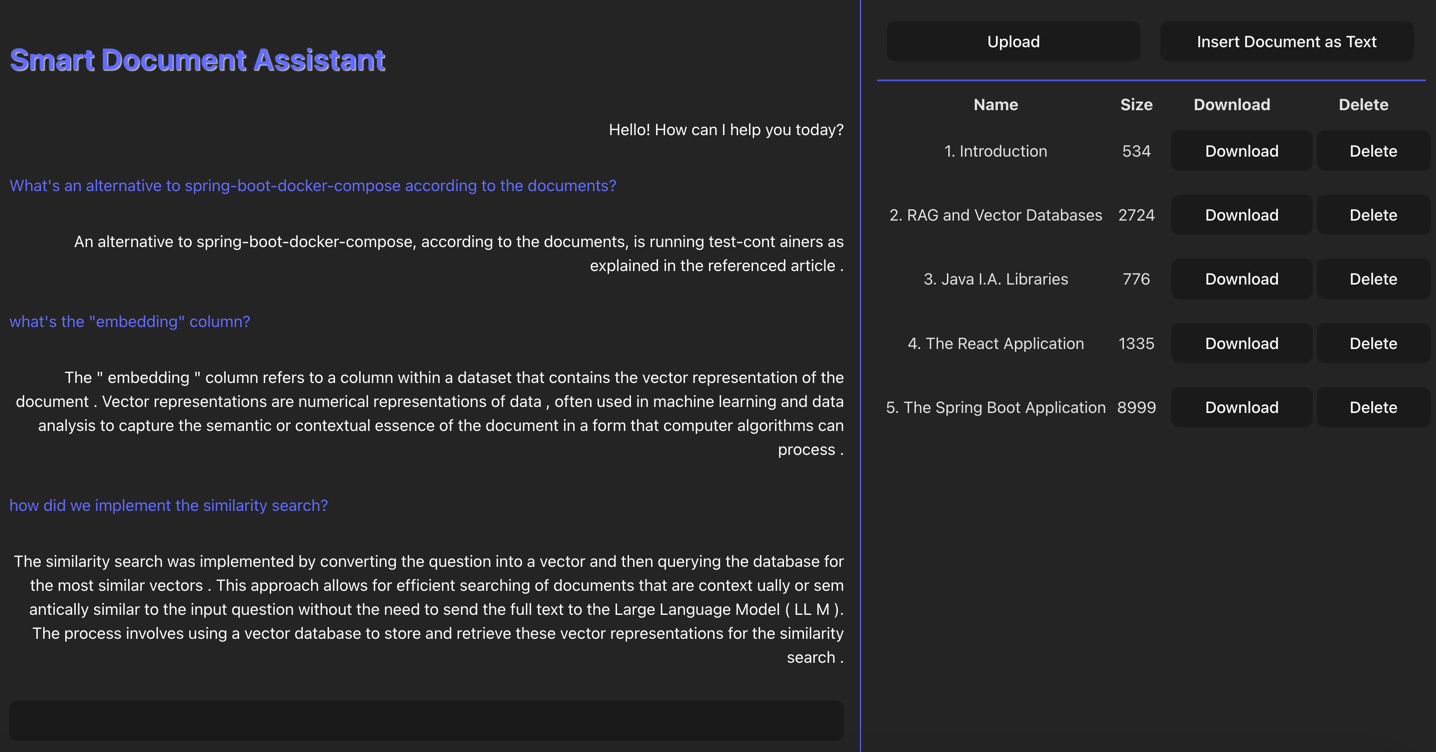
Final Testing Screenshot.
The output is quite good, and it’s able to answer the questions in a more specific way than a standard LLM. Of course, the more documents we feed regarding our specific use case, the more accurate the answers will be. Also, we should fine-tune the similarity search parameters and the tokenizer to make the assistant more accurate.
7. Future Improvements
I tried to include here only the pieces of code that I find more interesting for demo purposes, but I really encourage you to visit the repository linked at the end of the article to see the full code and experiment a little.
The repository is open to pull requests if you want to:
- Fix UI/UX issues in the React application
- Use WebFlux to handle the chat response instead of blocking calls
- Parametrize TokenTextSplitter to split the text in a user-defined way
- Parametrize the similarity search and chat assistant to use different distance types and thresholds
- Do and propose any other fix or improvement
In the next articles, we could:
- Enhance the LLM response with more complex templates and Structured Generation
- Implement an Alexa skill to talk with the Smart Document Assistant directly by voice.
- Implement a semantic cache to improve the RAG system.
- Experiment with different similarity search algorithms and databases.
- Include Images and parsed snippets of code in the Chat response
8. Thanks
The SpringDeveloper YouTube channel contains a lot of useful information about Spring AI and Java AI in general. The JFocus conference videos are also a good source of information about AI in Java. I suggest you to subscribe to it. This article was made mostly thanks to the following videos:
- Spring Tips: Vector Databases with Spring AI
- Unleashing AI in Java: A Guide to Semantic Kernel, LangChain4j, and Spring AI by Marcus Hellberg
But most of all thank you all for spending some time reading this article! I really put my time and effort into this, so if you want please consider sharing.